摘要
本文提出一个无监督的基于密度的用于异常检测的方法
目的:定义一种平滑而有效的异常度量,可用于检测非线性系统中的异常。
局部离群值得分(local outlier score, LOS):该方法为每个样本分配一个局部离群值分数(local outlier score, LOS),表明一个样本在其位置上与其他样本的偏差程度。具体为,一个样本与其一组相邻样本之间的局部密度的相对度量。
==自适应和宽度:在高密度区域,我们应用宽核宽度来平滑正常样本之间的差异;在低密度区域,我们使用狭窄的核宽度来强化潜在异常样本的异常。==
简介
对于复杂系统,线性逼近很容易导致问题的不拟合,导致较大的偏差
在本文中,我们只考虑无监督、基于知识的、数据驱动的异常检测技术。
本文提出了一种基于自适应核密度的异常检测(adaptive kernel density-based anomaly dection, Adaptive-KD)方法,用于检测非线性系统中的异常。该方法是基于实例的,并为每个样本分配了一定程度的异常值,即局部离群值分数。具体来说,局部离群值得分是一个点和其一组参考点之间的局部密度的相对度量。测量局部密度通过光滑核函数定义。
==创新点:在计算局部密度时,核宽度参数根据一个候选点到其邻近点的平均距离自适应设置——距离越大,宽度越窄,反之亦然。==使用该方法的好处在于增强了异常值测量的判别能力,可以突出潜在异常点与正常点之间的对比,并平滑正常点之间的差异,这是非线性异常检测应用所需要的。
相关工作
非参数密度估计可以通过核方法或k最近邻方法来实现。前者使用固定大小的区域中样本个数的信息,而后者考虑包含固定数量样本的区域的大小。
设
Parzen窗口估计
低概率密度可能意味着样本的出现不符合底层数据生成机制,因此表明可能存在异常,反之亦然。
对于样本
其中
为了实现密度估计的平滑性,需要一个平滑核。平滑核是一个参数的函数,它满足
异常检测方法:为了检测给定集合
优点:Parzen窗口估计没有对数据分布的假设,因此具有实际意义
缺陷:它在检测包含几个密度有显著差异的集群的数据集中的异常时可能表现不佳。
如图1所示:O点(红色星号)是靠近密集簇C1(蓝点),远离分散簇C2(黑点)的异常点。假设选择L2范数作为距离测度,采用宽度为
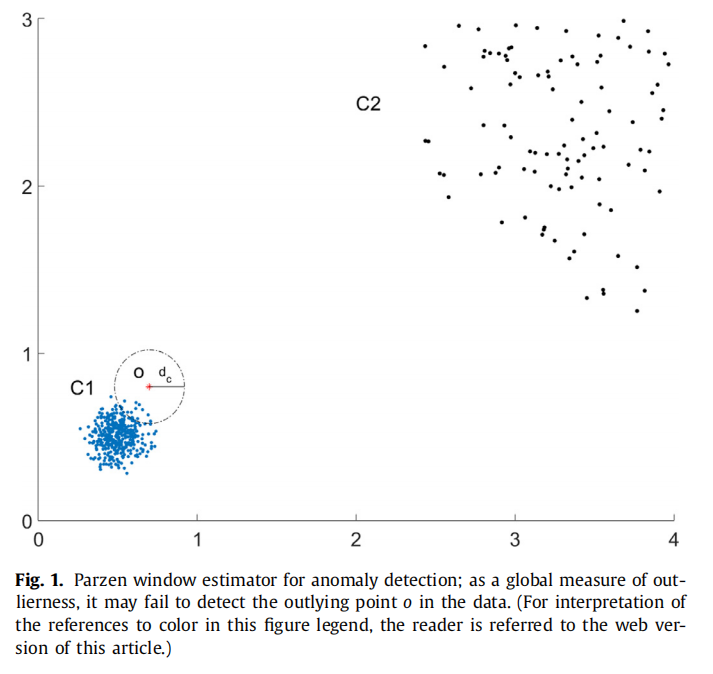
如果我们忽略归一化常数,用公式(1)计算出来的
如果阈值设置的高,虽然能捕获到异常点 o,但也可能导致较高的误报率,因为这里的密度估计是全局度量。
因此,它缺乏从密度较小的簇C2中的那些点中区分异常点o的能力。除此之外,不建议使用公式(1)中固定的核宽度从正常样本中分离潜在异常。
局部离群值因子(Local outlier factor,LOF)
局部离群因子(LOF)方法根据包含
其中
直观地说,局部可达密度可以反映包含一个点的k个最近邻居的区域大小。局部可达密度越小,该点的越可能是离群点,反之亦然。
然而,局部可达性密度不一定是局部离群值的度量。它可能会遇到图1中使用Parzen窗口估计器进行异常检测的问题。为了解决这个问题,LOF定义了一个次要度量,一个局部离群因子,来度量局部离群值。第
这是一个相对度量,计算一个点的
通常,局部离群因子在1附近(或小于1)的点应该被认为是正常的,因为它们的密度大致等于(或大于)它们邻近点的平均密度。局部离群因子显著大于1的点更有可能是异常点。
局部离群值度量的关键点: **==将一个点的度量与其参考点点的度量进行比较==**。比如将一个点的局部可达密度与其周围的
缺陷:
- 局部可达密度不平滑。这可能导致局部离群值度量不连续
- 对于输入参数(最近邻的数量)比较敏感。错误选择该参数很容易隐藏数据中的结构,如图5(1d)所示
基于核密度的自适应异常检测方法
本文将将上述两种方法结合起来,得到一种平滑的局部离群度量,能够从非线性数据中检测出异常。
LOF方法提供了定义局部离群值的基本方案,而在Parzen窗口估计方法中使用核函数的思想有助于导出平滑密度估计。为了增强局部离群测度的鉴别能力,我们使用自适应的核带宽。
该方法的一般思想
Adaptive-KD 的方法试图定义一个函数
Adaptive-KD方法遵循LOF方法的基本步骤来获取局部离群度量:
- 定义参考集,推导主要度量(局部密度)
- 基于主要度量和参考集计算次要度量(局部离群)
在第二步中,为了实现局部离群度量的平滑,采用Parzen窗估计的思想,使用平滑的核函数来定义主要度量。为了增强对正常样本和异常样本的区分能力,采用了自适应核宽度的方法。
一般方法是在高密度区域应用较小的带宽
Silverman规则使用点到其
其中,
==在异常检测的背景下,核宽度的优选设置与密度估计问题中的设置正好相反。也就是说,高密度区域优先选择较大的宽度,低密度区域优先选择较小的宽度。==
原因:
- 在高密度区域,虽然可能有一些有趣的结构,但我们通常对它们不感兴趣,因为它们在试图区分异常和正常样本时没有信息。
- 在高密度区域进行过平滑密度估计可以减少正常样本局部离群度量的方差,有助于区分异常。
- 在低密度区域,采用较小的带宽,会使得来自核的“长尾”部分的贡献大大减少,从而导致更小的密度估计。这可以使异常点突出,增强方法对异常的敏感性。
利用自适应核宽度计算局部密度
我们用
公式7中的右式不包括第
高斯核函数的定义
- 当
比较大时,取个倒数就变成了很小的一个系数,此时向量 和 之间距离的变化对指数整体数值的影响就会变小,此时 的变化也会比较 “平滑”。 - 同理,当
比较小时,让向量 和 之间距离的变化对指数整体数值的影响变大了,此时 的变化会变得比较 “尖锐”。
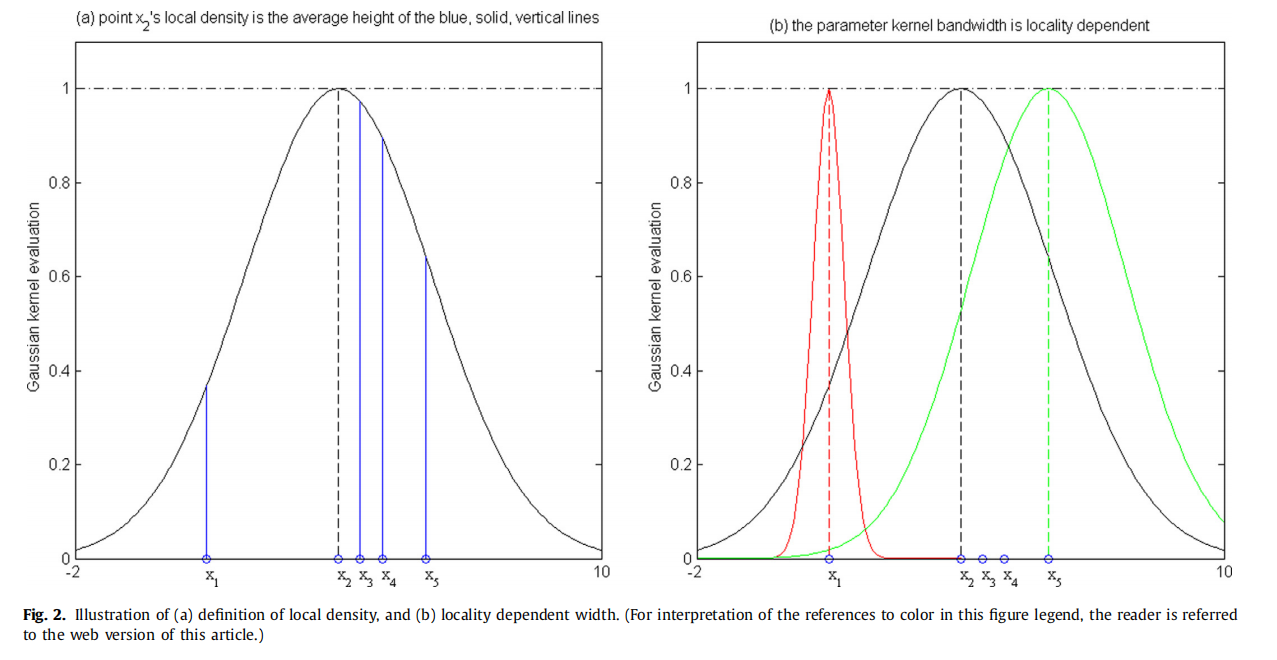
对一个点的局部密度的简单解释如下:使用高斯核对局部范围内的点进行卷积,每个点的平均贡献。一个更直观的解释如图2(a)所示。点
当带宽趋于无穷时,图中的高斯函数对应的曲线将会趋于平坦,
当带宽趋于无穷小时,高斯函数就变成了狄拉克函数。这意味着只有在给定数据集中的那些点的密度为非零,而其他点的密度为零。这就解释了为什么一个小的带宽会加剧点之间的密度差异。
宽度
对于第
其中
公式(8)中的核宽度
计算局部离群值
第
对上述数量的一个直观解释是,它是一个点的最近邻的平均局部密度与它自身的局部密度的相对比较。
模型集成及其在线扩展
Adaptive-KD伪代码如图3所示。其中的特征归一化是对不同特征的数值范围进行标准化的一种重要技术。它避免了在以后的计算中,较大数值范围的特征支配较小数值范围的特征。在异常检测应用中,我们推荐使用Z-score归一化而不是MinMax缩放,因为后者可能会抑制异常的影响。Z-score 方法将给定的矩阵

通常,在线异常检测任务分为离线模型训练和在线测试两个阶段,如图4所示。在无监督的环境中,第一阶段试图学习正常行为;第二阶段在新生成的样本到达时,将其与学习到的正常模式进行比较。测试时,将样本偏离正常模式的程度作为判别异常和正常样本的依据。
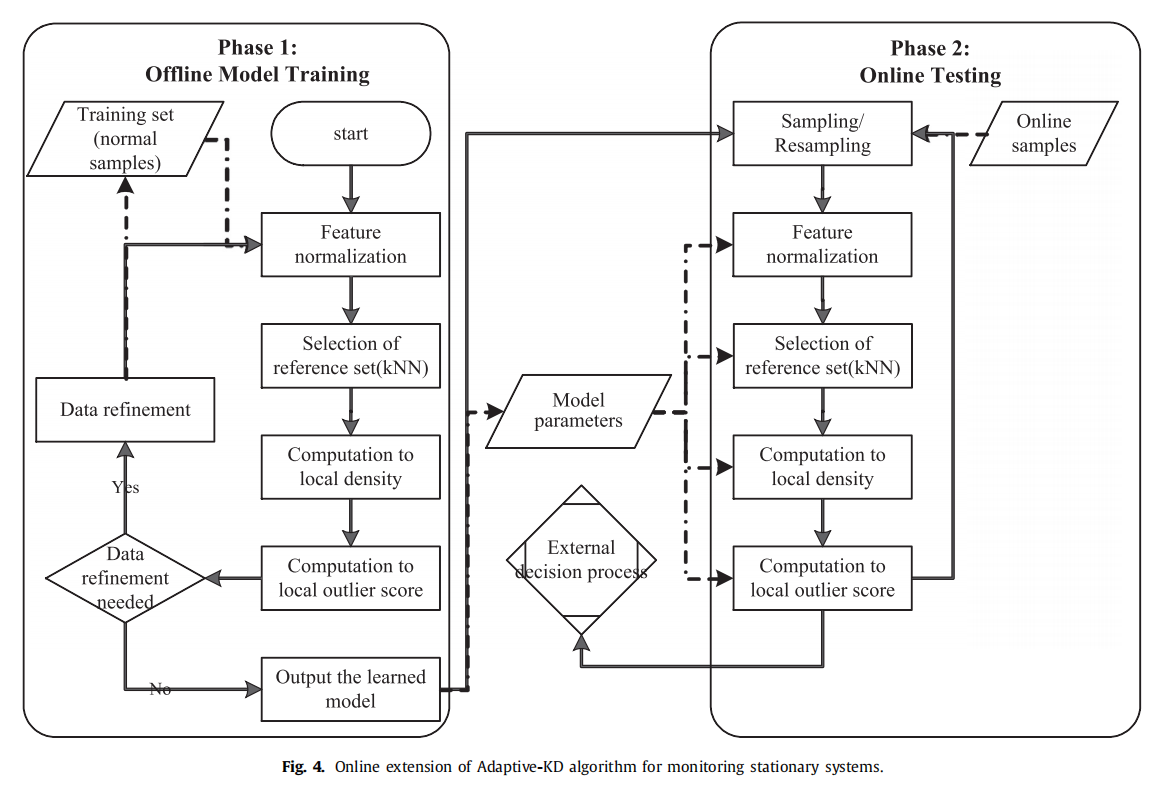
离线模型训练阶段如图4所示,基本遵循图3中Adaptive-KD算法的流程。由于该阶段旨在学习系统正常行为的模式,因此需要精心选择无异常样本来构建训练集。因为正常用本中的异常的存在可能会降低测试时时样本的局部离群值得分,所以我们添加了一个数据精炼程序,从训练集中排除那些具有非常高的局部离群值的样本,然后重新训练模型。该方法偏主观。
在第一阶段学习到的正常模式作为模型参数,在第二阶段使用。值得注意的是,我们的模型参数在训练后是固定的。这个在线扩展的基本假设是,系统的正常行为不会随着时间的推移而变化(数据流中没有概念漂移)。我们可以定期对模型进行再训练,以吸收系统中的正常变化。
在测试阶段,在线样本到它们的
复杂度
算法中计算最密集的步骤是
局部密度计算的复杂性在于高斯核计算,这主要是因为高斯核具有无界支持度。换句话说,对于每个点,高斯核函数需要对所有剩余的点求值。
与离线模型训练阶段一样,在线测试阶段对计算量要求最高的步骤是
实验结果
该部分将Adaptive-KD 与 SVDD 和 KPAC 进行比较。
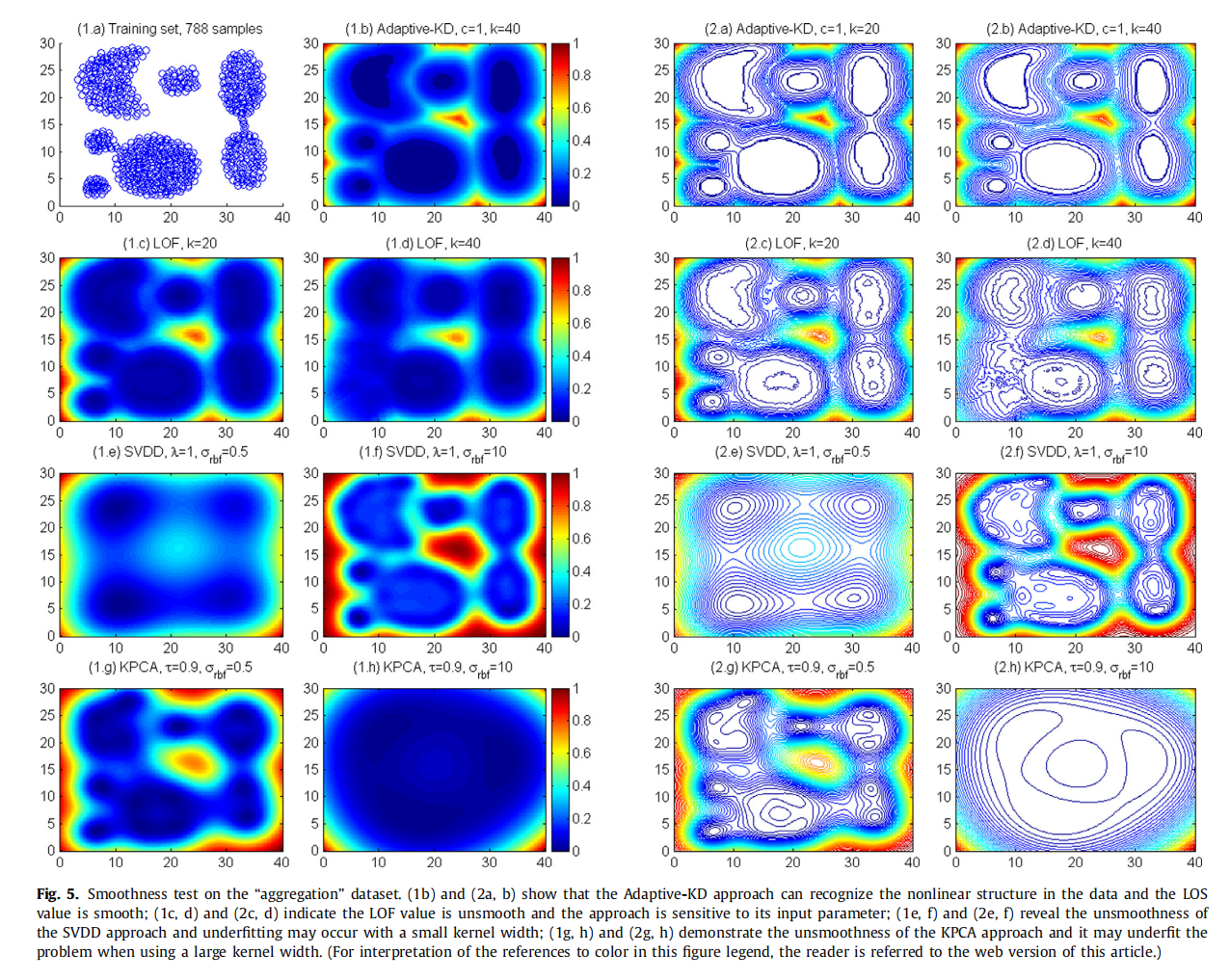
使用“聚合”数据集进行平滑性测试
如图5(1a)所示,数据集包含788个样本,形成7个不同的聚类。
Adaptive-KD
如子图(1b)和(2b)所示,我们的方法可以正确地检测聚类的形状,并给出一个非常平滑的局部离群值度量。此外,本例中的结果对参数k的变化具有相当的鲁棒性。当参数k = 20时等高线图的另一个例子是在子图(2a)中。注意,在集群核心中,局部离群值几乎相同。这是由于高密度区域大核宽的平滑效应造成的**。
LOF
虽然LOF方法可以在
SCDD
如(1e)所示,当核宽度较小时,SVDD方法容易欠拟合,无法检测到数据集中簇的形状。当
KPCA
与SVDD方法不同,当
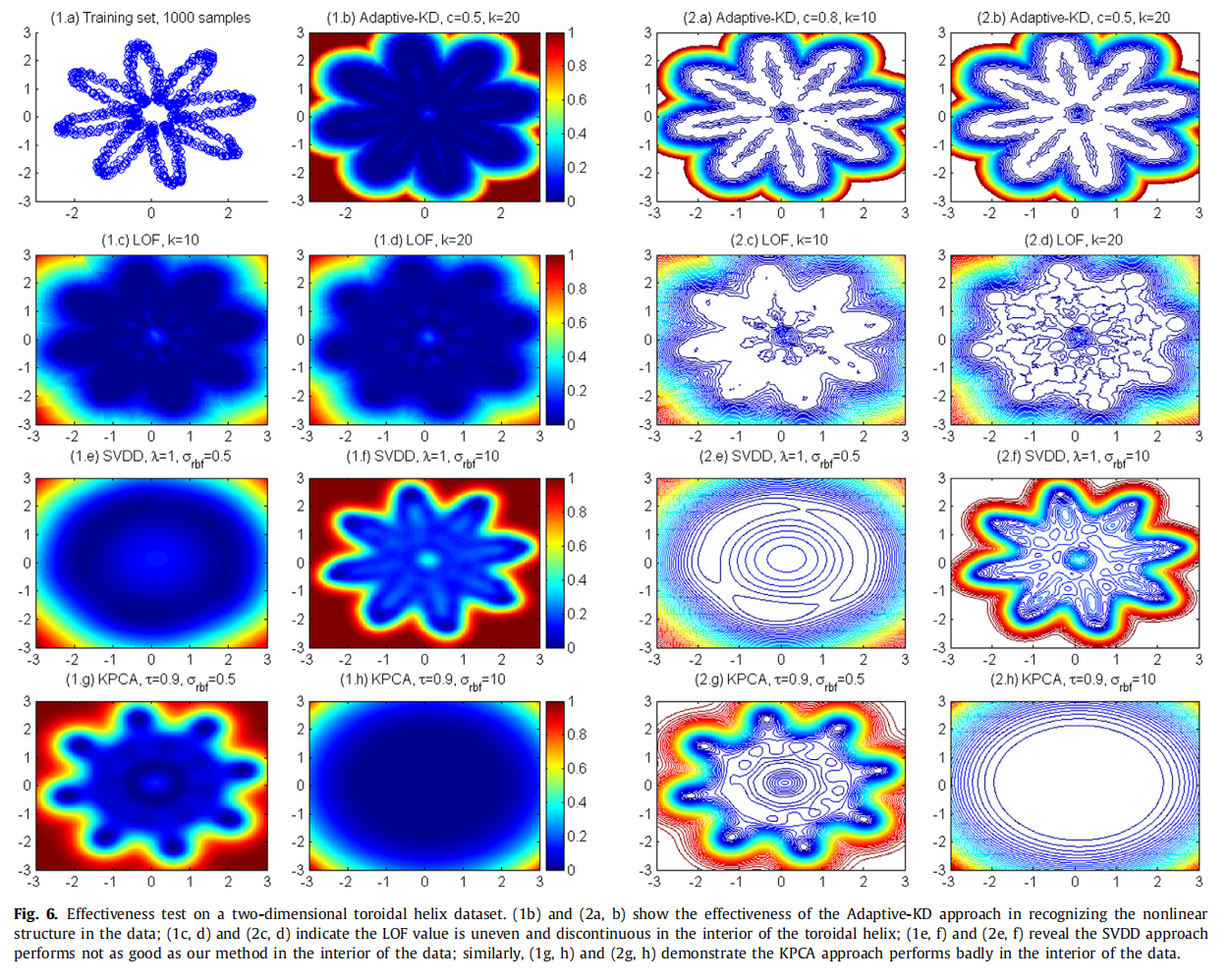
使用高度非线性数据集的有效性测试:二维环形螺旋
我们将这些方法应用于一个高度非线性的数据集,并比较结果。在本例中,训练集是一个包含1000个样本的二维环形螺旋,如图6(1a)所示。
Adaptive-KD
我们的方法可以有效地检测到数据的形状,等高线图平滑地向内外凹陷波动,如图6 (1b)和(2b)所示。
LOF
同样,LOF方法可以在一定程度上识别数据的形状,但等高线图是相当不均匀的,并且在测量局部异常值方面的不连续是显著的,特别是当k取较大值时。
SVDD、KPCA
SVDD方法在内核宽度较大时检测形状,而KPCA方法在宽度参数较小时工作。SVDD在环形螺旋内部的表现似乎比KPCA更好,但三种方案的离群性测量并不像我们预期的那么平滑。
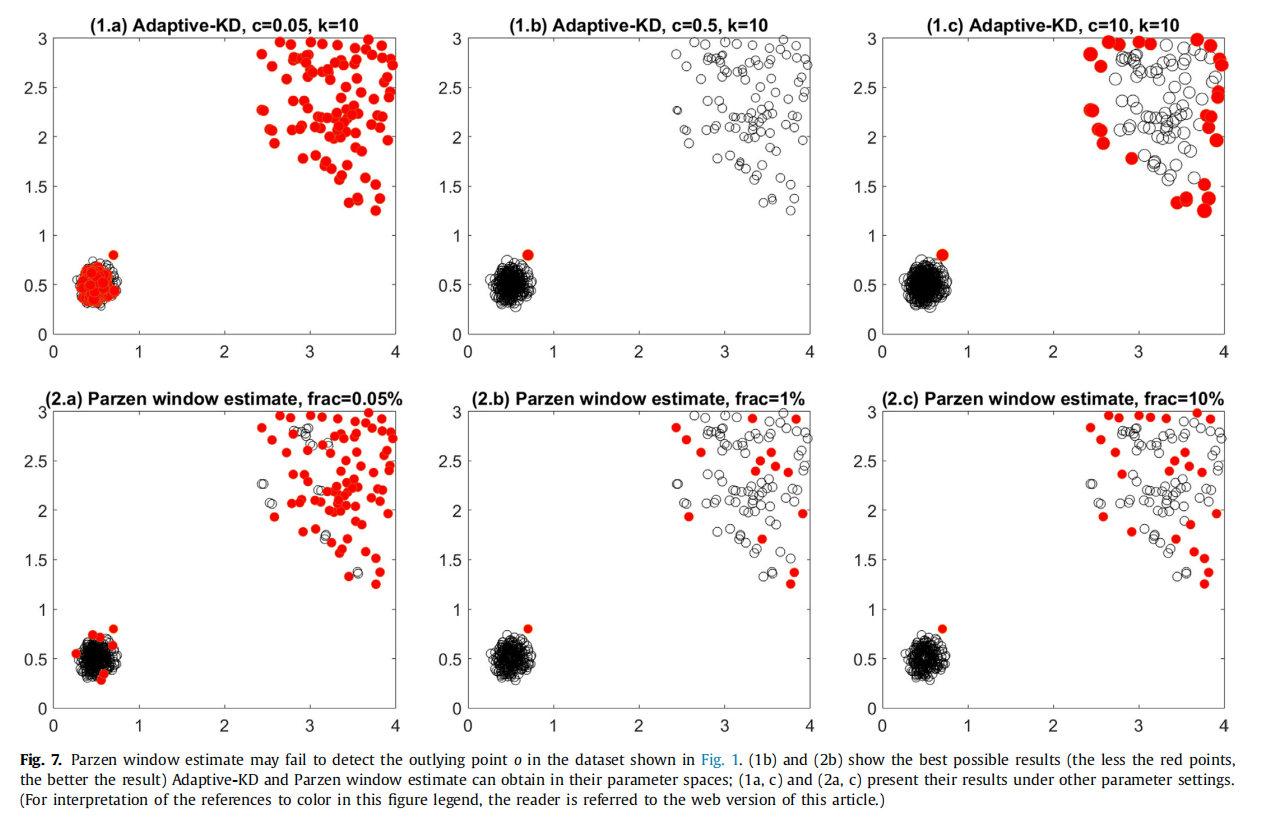
一般来说,较小的
使用图1中的数据
一个经过调优的核密度估计器中获得的整体异常值度量可以在这些例子中实现类似的平滑性,但它可能在集群密度有显著差异的数据集中失败。如图7所示。那些离群值大于或等于
这个实验澄清了我们关于当数据显示不同密度区域时,使用Parzen窗口估计在离群值检测中的缺陷的主张。此外,它还说明了使用我们的方法的好处。
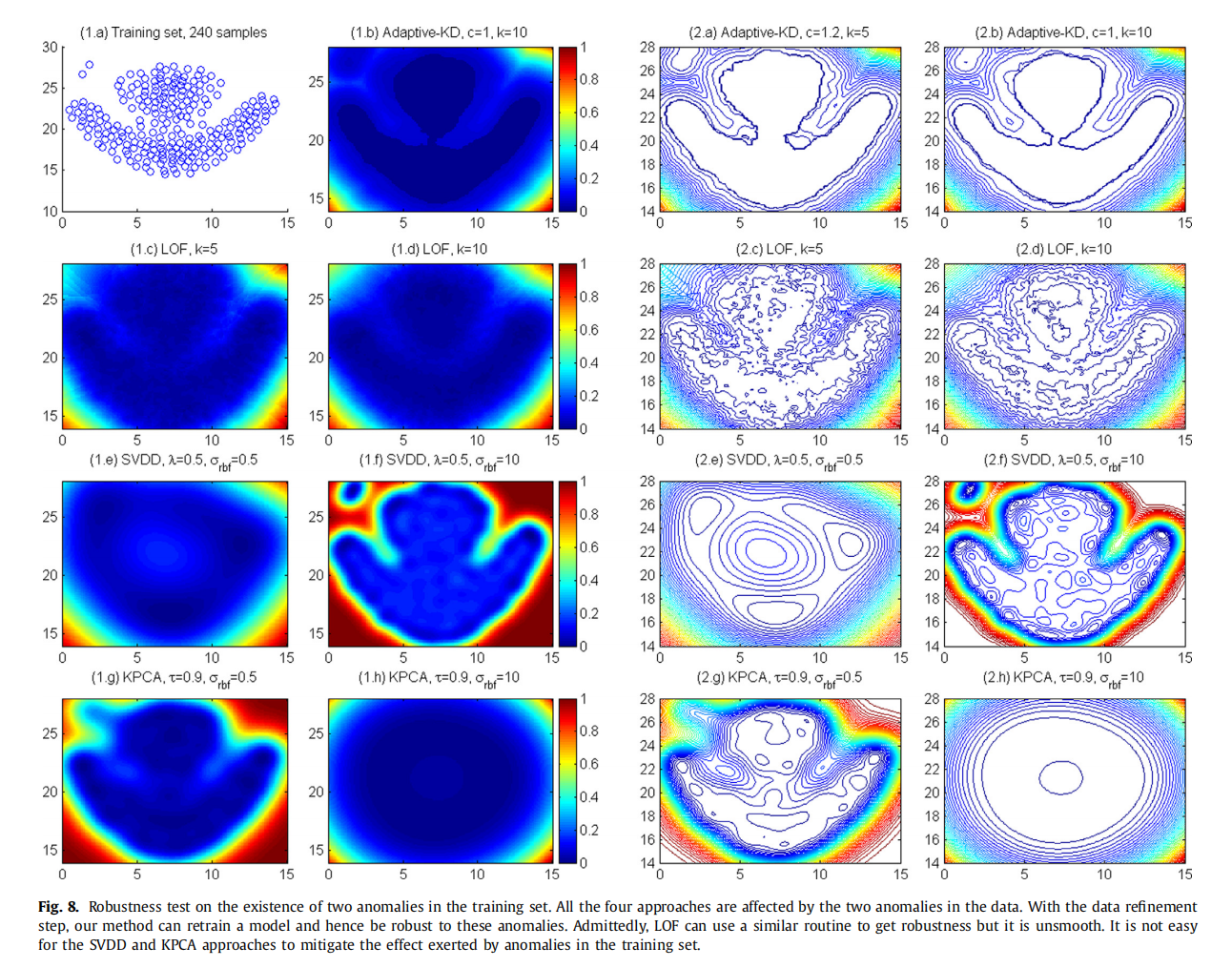
使用“flame”数据集进行鲁棒性测试
使用“flame”数据集来确定训练集中异常的存在如何影响各种方法。我们还讨论了我们的方法对输入参数扰动的鲁棒性。“flame”数据集如图8 (1a)所示,左上角的两点被认为是异常点。
Adaptive-KD方法自然能够将局部离群值分配给训练集中的任何样本。因此,离线训练阶段的数据精炼步骤应该能够捕获和丢弃这两个异常,并在精炼集上重新训练模型。
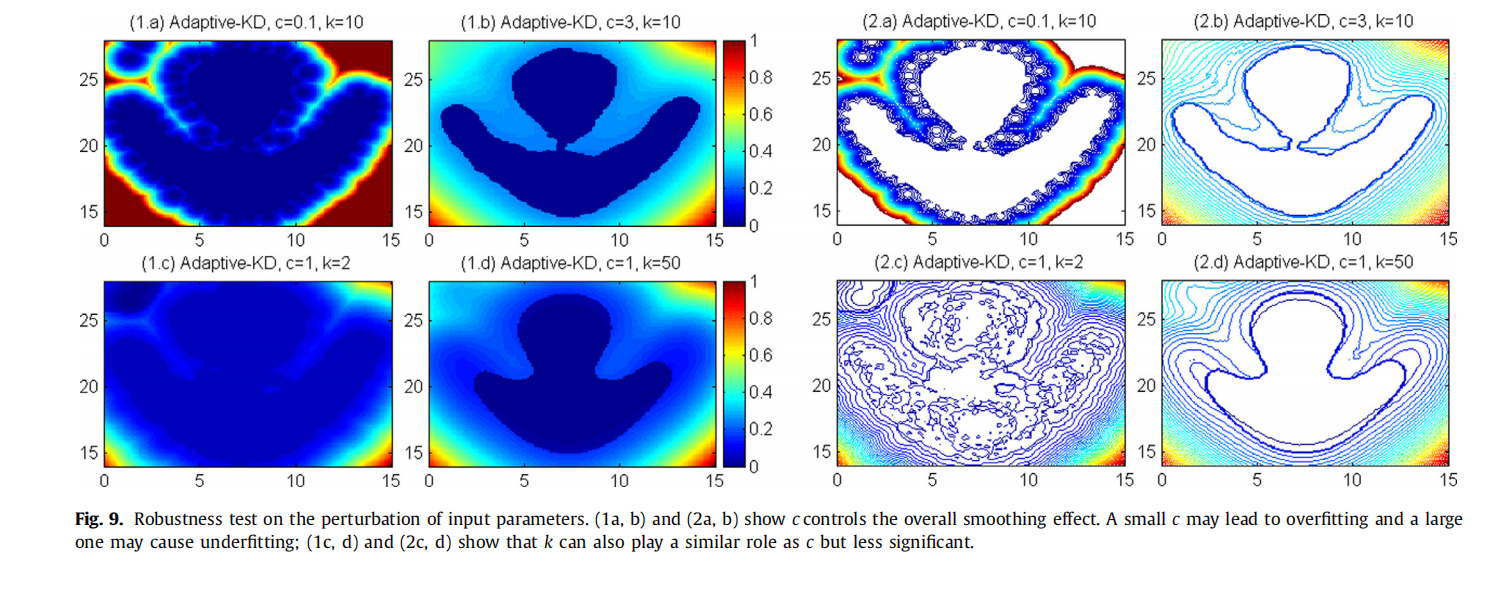
输入参数的扰动对Adaptive-KD方法的影响
参数c
如图9(1a)和(1b)所示,相应的等高线图如图(2a)和(2b)所示
参数c直接控制整体平滑效果。较小的c可能会增强数据中的精细细节,导致过拟合,而较大的c可能会导致过平滑和欠拟合。注意,当选择较大的c时,训练集中异常的影响可以在一定程度上抵消,因为两个异常处的局部信息被平滑了。
参数k
如图9(1c)和(1d)所示,相应的等高线图如图(2c)和(2d)所示
由于参数k对核宽度的尺度有间接的影响,所以它可以以类似于c的方式影响平滑效果。
与其他无监督学习方法一样,Adaptive-KD方法依赖于点之间的相似性(或不相似性)测量。具体来说,LOS计算的是一个点的局部密度与其
k还决定了参考集的数量,从而影响了局部离群测度。
- 如果k取的值非常小,则极少数参考点的局域密度可能会主导该点局域离群值得分的计算,从而导致离群值测度的不连续,如图9 (2c)所示。这就解释了(2c)中所示的等高线图在k取很小的值时内部会有很大的波动。
- 在极端的情况下,当k取训练集大小的值时,LOS恢复到一个全局的离群性度量。式(9)中的分子对于每个点都是相同的,离群性度量的排名仅仅是局域密度的排名的倒序
根据我们在上面三个例子中的实验,只要参数
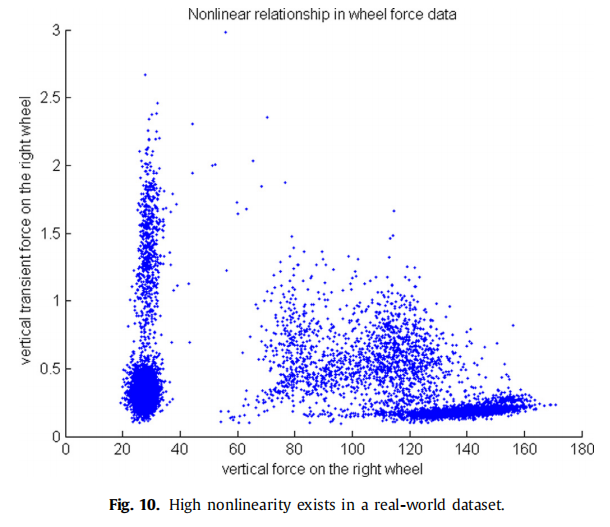
使用真实世界的数据集进行验证
图10显示了数据中不同密度的聚类,可能对应于不同的装载重量、操作模式等。
最终数据集包含9970个样本,其中30个为异常。数据有八个维度。
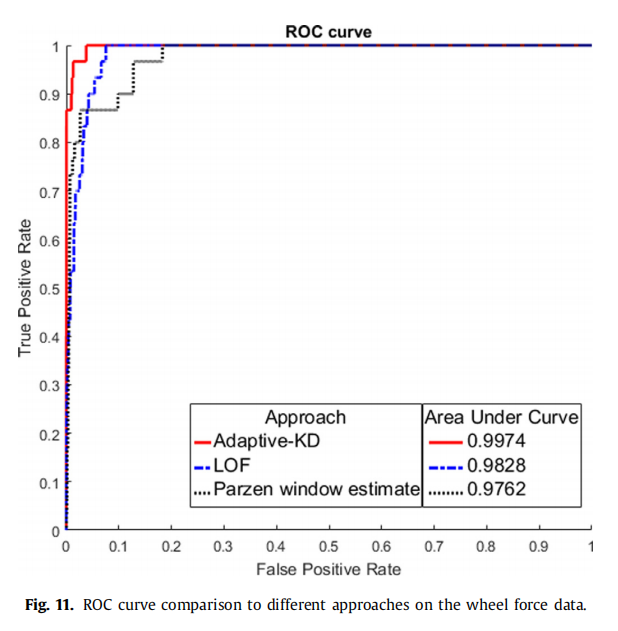
如图11所示,Adaptive-KD方法在精度上优于其他两种方法。
在我们的方法中,在所有的计算中,都可以追溯到点的
总结
本文提出了一种基于非监督密度的非线性系统异常检测方法。像许多其他无监督学习方法一样,它使用不同点之间的相似性度量,并为每个点分配一个异常度,即局部离群值(LOS)。LOS在这里被定义为一个点与其相邻点集之间的局部密度的相对度量,而局部密度是评估一个点与其相邻点之间相似性的相似度度量。为了使测度平滑,我们采用了高斯核函数。为了增强度量的鉴别能力,我们使用了依赖于局部性的内核宽度:宽的内核宽度应用于高密度区域,而窄的内核宽度用于低密度区域。通过这样做,我们可以模糊正常样本之间的差异,强化潜在异常样本的异常。当采用Silverman规则时,对不同密度区域的识别就变成了对密度的粗略估计,即从一点到它的
根据实验,我们得出以下结论:
- 该方法能够识别数据中的非线性结构。
- 所提出的局部离群值是一种平滑测度。此外,簇心处的局部离群值基本相同,而簇晕的离群值明显较大。这表明局部依赖的核宽度可以增强异常检测任务的分辨能力。
- 随着数据细化步骤的增加,所提方法的在线扩展对训练集中异常的存在具有更强的鲁棒性。它对参数
的变化也比LOF方法更稳健。 - 该方法的可解释性远大于其他从输入空间到特征空间隐式进行非线性转换的核方法。
- 在工业数据集上的实验证明了该算法在实际应用中的适用性。
以下考虑留给未来的工作:
- 我们的方法可以扩展到在时间上下文中检测非平稳数据流中的故障,例如使用滑动窗口策略。
- 使用其他具有紧凑支持的平滑核函数可以加快计算速度,但使用其他核函数的影响需要充分研究。